Кто-то быстренько заимплементил свою версию. По инерции своя версия поддерживалась какое-то время, пока не стало понятно, что задача сильно осложняется различными вариациями формата CSV, различными формами экранирования, обработки пустых значений, выяснилось, что и формата есть несколько вариаций. Код оброс специальными случаями и условиями, стал нечитаем.
Задача стандартная, возник запрос, зачем делать самим. Быстрый поиск по интернету готовой версии выдал несколько левеньких вариантов со своими проблемами, а также более серьезные версии типа FileHelpers. Более серьезные версии как выяснилось не очень вписываются в нашу структуру классов. К примеру, FileHelpers как бы десериализует запись в объект класса. Звучит неплохо, однако для каждой колонки в целевом классе нужно было поле. А у нас файлы по 200-400 колонок.
Попробовали порефакторить – не впервой. Пошаговый рефакторинг не сильно улучшил ситуацию, попытки придумать новый подход тоже как-то не дали результата. В итоге все же наткнулись на идею написать парсер в виде конечного автомата – догадались не сами, но все же.
Конечный автомат – это по сути набор состояний системы и переходов из одного состояния в другое. Паттерн State эксплуатирует это математическое понятие. У каждого состояния есть свой способ обработки этого состояния и свои правила перехода в другие состояния. Конечный автомат также легко визуализируется при помощи UML State Chart диаграммы (ниже можно увидеть упрощенный пример).
Неожиданным плюсом оказалось также то, что конечный автомат в .NET делать очень просто, делегаты делают код простым и понятным.
Основная задача - распарсить одну строку файла:
private string[] SplitCsvLine(string line)Идея в том, что мы пробегаемся по символам в строке и при встрече какого-либо специального символа мы переходим в новое состояние. В разных состояниях один и тот же символ переводит в различные состояния. Пример:
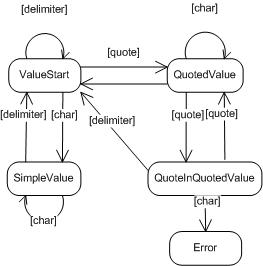
Код перехода из состояний в состояние:
CsvStateHandler currentState = HandleValueStart; for (int i = 0, lineLength = line.Length; i < lineLength; i++) { currentState = currentState(line[i], currentValue, values); }CurrentState – это делегат вида:
private delegate CsvStateHandler CsvStateHandler( char currentChar, StringBuilder currentValue, List<string> values);
Пример обработчика состояний:
private CsvStateHandler HandleValueStart( char currentChar, StringBuilder currentValue, List<string> values) { currentValue.Clear(); if (currentChar == quoteChar) { return HandleQuotedValue; } if (currentChar == delimiter) { values.Add(String.Empty); return HandleValueStart; } currentValue.Append(currentChar); return HandleSimpleValue; }Таким образом сложные многоэтажные ифы превратились в одноуровневые простые и целиком распределелись по простым компактным методам. Изменение логики и добавление очередного перехода стало простым и быстрым. Код стал понятен и поддерживаем.
хех, это только в начале всё так просто. с учётом заквотированых переносов строк и различных типов переносов - задача не такая простая.
ОтветитьУдалитьнапример:
1st row,abcd\n,"e,f""g","h\n\ri"\n\r2nd row,j,k,l
здесь \n\r - новая строка
Ну, решали и такую проблему. Попозже слегка. Я выкладывал, кстати, код на github в следующей статье. Если честно, не помню, сделали мы уже там переносы строк или нет, но вот ссылка - продолжение
ОтветитьУдалить